

Com o crescimento na geração de dados e o avanço das tecnologias, hoje podemos utilizar dados para gerar conhecimento ou auxiliar na tomada de decisões utilizando aprendizado de máquina. A partir disso, iremos inevitavelmente nos deparar com um problema que acontece corriqueiramente. Dando continuidade à série sobre aprendizado de máquinas, hoje vamos tratar sobre desbalanceamento de dados. Você sabe o que é e como lidar com esse tipo de problema?
O que é desbalanceamento de dados?
O desbalanceamento de dados é um problema e deve ser levado em consideração. Apesar de alguns dados serem naturalmente desbalanceados, isto é, quando existem mais dados de uma classe em relação a/as outra(s), como é o caso de dados relacionados à fraudes, onde assumimos que maior parte das pessoas não são fraudadores, por motivos óbvios, iremos nos deparar com esse “desbalanceamento”. Em situações que fogem dessa “naturalidade” de dados desbalanceados, há alguns porquês por trás disso.
Erro na coleta dos dados é um tipo erro comum e as consequências disso são análises enviesadas, justamente pelo não equilíbrio entre as classes. Esse tipo de erro pode acontecer por meio de:
- Softwares que realizam coleta de dados;
- Coleta manual (por exemplo fichas médicas ou até mesmo cientistas de dados coletando dados para suas análises);
- E o mais natural: falta de dados. Como o exemplo dos “fraudadores” que mencionei logo acima.
Nesse cenário, a maneira mais direta, digamos, de resolver esse problema é checar se existe a possibilidade de coletar mais dados a fim de balancear as classes. O problema mesmo mora quando não existem mais dados da classe faltante para serem coletados e então, diferente da abordagem “coletar mais dados”, isso passa a não ser mais uma opção.
Felizmente, para determinados problemas, existem métodos para contornar essas situações sem a necessidade de coletar ou gerar mais dados. Existem algoritmos que tratam desse desbalanceamento e é sobre o conceito por trás deles que vamos conversar agora.
No contexto “não há mais dados para coletar” uma maneira de balancear é gerando mais dados. Supondo que você trabalhe em uma banco e está desenvolvendo um modelo preditivo capaz de classificar entre “fraudador” e “não fraudador”, a não ser que você tenha dados que contenham uma densidade de informação suficiente para o modelo, você terá que gerar mais dados.
Mas por que ter mais de uma classe do que de outra é um problema?
O déficit de amostragem é um problema, especialmente, quando estamos trabalhando com aprendizado de máquina para classificação e isso é compreendido quando adentramos um pouco mais a fundo para entender como os algoritmos interpretam os dados que estão sendo oferecidos.
Os algoritmos tendem a considerar mais importante a classe majoritária e isso faz com que o modelo aprenda mais sobre uma classe do que de outra. Em um exemplo, que considere a classe A mais importante, as classes B, C, D… n, que são as classe minoritárias, são consideradas como “menos importantes”.
Isso porque o modelo perde a capacidade de generalizar, pois está “viciado” na classe majoritária. Os modelos entendem algo mais ou menos assim: “Já que essa classe aparece em menor número de vezes, não há muita importância, então vamos focar na classe majoritária!”, o que impacta no resultado do modelo e é algo que precisa ser analisado cautelosamente.
Veja bem, se estamos criando um programa que vai identificar, a partir da expressão de marcadores moleculares, uma X doença rara. Sabendo que essa doença X é uma condição rara, inferimos que há poucas observações dessa classe, certo?! Quando treinamos o nosso modelo, verificamos que a acurácia geral gira em torno de 91%, o que seria muito bom!! Porém depende…
Nessa situação, muito provavelmente, existe um problema: o nosso algoritmo performou bem para o grupo que não apresenta a doença, porque é a classe majoritária, pois assumimos que se trata de uma doença rara. Nosso modelo aprendeu a identificar pessoas que não têm a doença, classificando pessoas com a doença em questão como pessoas saudáveis.
Como lidar com esse problema?
Agora que entendemos quais os problemas gerados quando trabalhamos com dados que não estão balanceados, vamos as soluções: Existem técnicas para lidar com esse problema, e cada técnica assume uma abordagem diferente da outra, veja:
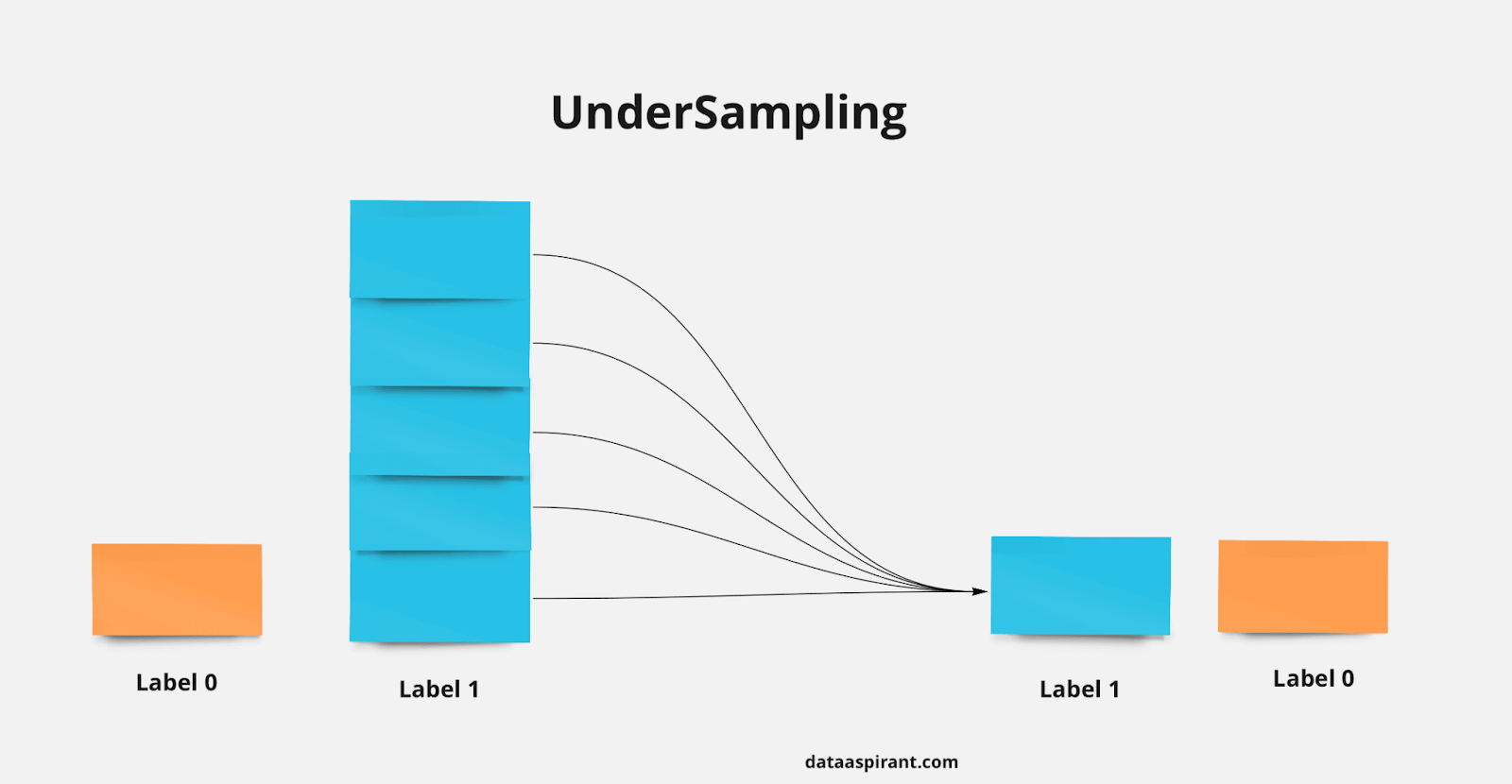
Undersampling
A técnica undersampling consiste em reduzir a classe majoritária de acordo com a classe minoritária. Em outras palavras, decidimos o quanto vamos diminuir a classe majoritária, pois queremos que a mesma seja similar a classe minoritária! Com isso, balanceamos os dados.
Oversampling
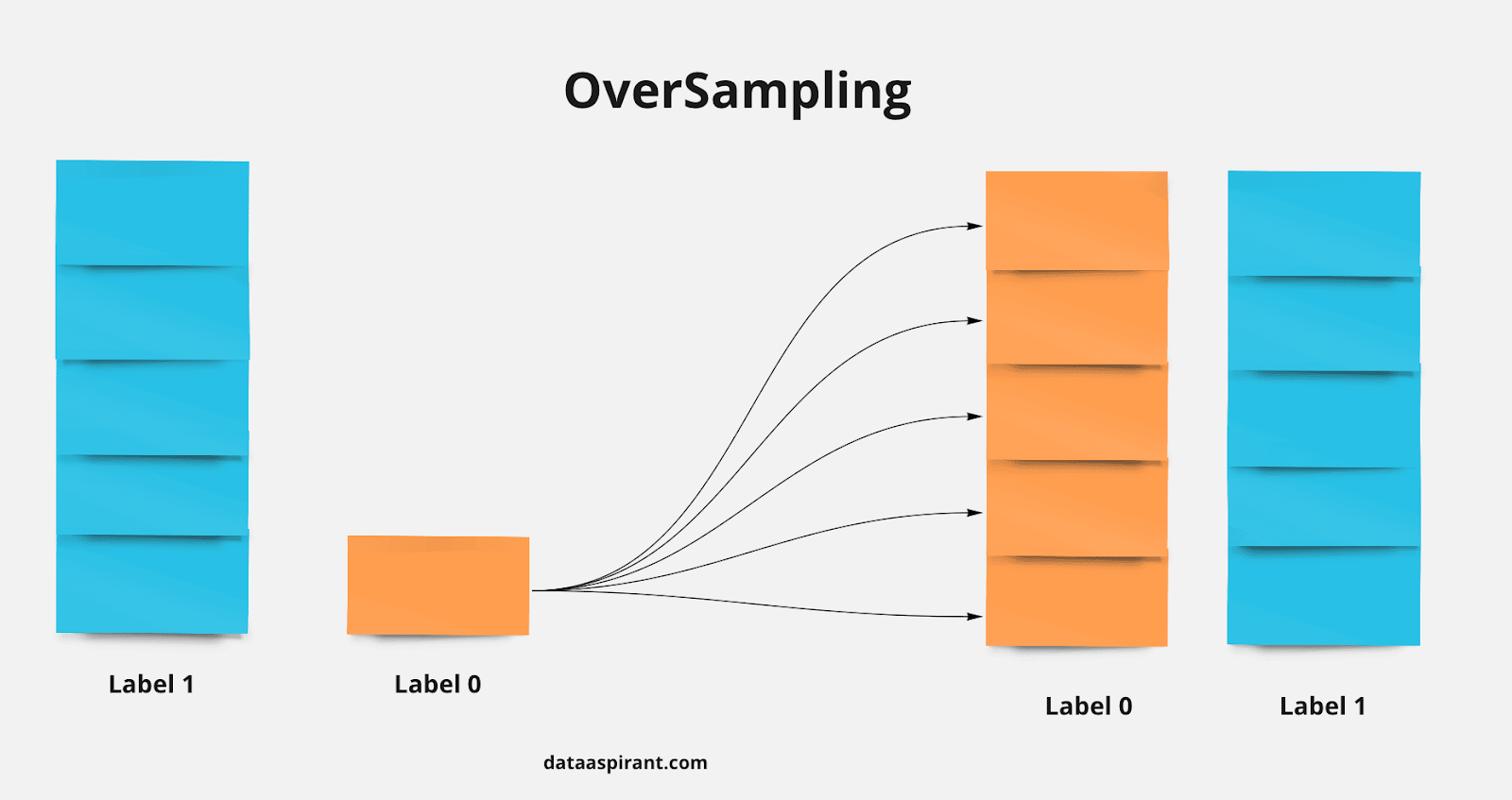
Diferente da técnica undersampling, podemos em vez de diminuir, aumentar a classe minoritária, assim não corremos o risco de perder dados importantes. Chamamos essa técnica de oversampling.
Riscos do uso das técnicas
Como geralmente toda técnica oferece um risco que precisa ser levado em consideração, essas não são exceções. Quando utilizamos undersampling, corremos o risco de perder dados ou não ter dados suficientes, gerando uma condição chamada de underfitting. Já com oversampling corremos o risco contrário, podemos gerar overfitting no treinamento, em outras palavras, fazer com que o modelo aprenda muito sobre os dados que foram oferecidos, tirando a capacidade do mesmo de generalizar o que foi aprendido.
Para contornar tanto o problema de falta de dados quanto underfit e overfit, existem sub técnicas, dentro de UnderSampling quanto Oversampling, e vamos chamar isso de funções! Essas funções procuram gerar ou diminuir os dados, porém seguindo abordagens diferentes. Veja:
Synthetic Minority Oversampling Technique (SMOTE)
SMOTE é uma técnica utilizada no tratamento de dados desbalanceados, gerando dados sintéticos a partir do conjunto minoritário. Diferente de outras técnicas, essa não replica observações do nosso conjunto de dados, e sim, gera novos dados – por isso dados sintéticos – que são semelhantes aos dados que já existem, porém com uma leve perturbação, que é o que os difere dos demais.
Esses dados sintéticos são gerados a partir da utilização de um algoritmo chamado K-nearest Neighbor. Mas afinal, como esse algoritmo funciona? O próprio nome dele já nos dá um leve spoiler: X (ou k) vizinho(s) mais próximo(s).
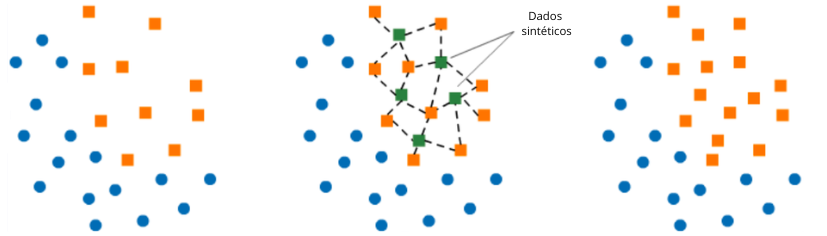
Inicialmente, a técnica SMOTE seleciona aleatoriamente uma observação da nossa classe minoritária. No segundo passo, o algoritmo em questão entra em campo, ele vai olhar para essa observação e vai buscar por X vizinhos mais próximos – os cinco vizinhos mais próximos, por exemplo – então o knearst neighbor escolhe aleatoriamente um ponto dentro desses cinco “vizinhos” mais próximos e então por meio de uma equação, a geração de um novo dado sintético acontece.
Tomek Links
Por outro lado, quando precisamos reduzir a classe majoritária, podemos utilizar a técnica T-link, também chamada de Tomek Links. Essa é uma técnica que visa reduzir o número de amostras de dados. Diferente da técnica anterior, onde dados são gerados de maneira sintética, nesta (T-link) há a exclusão. Mas o que de fato são Tomek Links?.
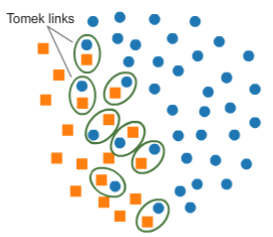
Tomek Links são pares de observações. Considere “observações” os pontos azuis e laranjas da imagem, que são unidades de um conjunto de dados de classes opostas que estejam o mais próximos possível, por exemplo, classe positiva e negativa, majoritária e minoritária.
Diferente do algoritmo responsável pela técnica SMOTE, esta segue a mesma premissa, porém com algumas modificações. Aqui, o algoritmo já não mais escolhe um número de vizinhos aleatórios mais próximos, mas sim o vizinho mais próximo. Para que tenhamos um “tomek link” o algoritmo segue algumas condições:
- O vizinho mais próximo de A é B.
- O vizinho mais próximo de B é A.
- Ambas observações (A e B) são de classes opostas, ou seja, minoritária e majoritária (ou vice versa).
A partir dessa identificação, a maioria das observações da classe majoritária serão excluídas, isso possibilita que a margem entre o que é classe A e o que é classe B se torne nítido. Comparando as figuras abaixo, iremos notar uma “fronteira” maior entre os pontos, fazendo com que a previsão das classes, de certa forma, seja facilitada.

Quais as aplicações dentro da biotecnologia?
Essas técnicas de balanceamento são utilizadas quando, por exemplo, estamos trabalhando com dados para desenvolver diagnósticos. Para muitos casos faltará dados de uma determinada classe, seja representações de pessoas que fazem parte do grupo de controle ou de pessoas que apresentam a condição observada (doença, características fenotípicas ou genotípicas), como também classificação de proteínas que apresentem potencial imunogênico; identificação de peptídeos anticancer, entre outros.
Os exemplos da utilização dessa técnica dentro da biotecnologia é extensa e varia de acordo com o escopo de cada pesquisa, como por exemplo na biotecnologia vegetal.
Supondo que você trabalhe em uma pesquisa relacionada a identificação precoce de doenças em morangos e está desenvolvendo um software que, a partir de fotos, identifica possíveis doenças. A não ser que você tenha dados que contenham uma densidade de informação suficiente para o modelo, você terá que tirar muitas fotos de morangos saudáveis e não saudáveis. Entende o quão custoso pode ser gerar dados?
É fatídico que iremos nos deparar com classes que possuem menores registros. Mas não se assuste! O desbalanceamento de dados pode causar sérios problemas se não tratados, justamente porque o modelo acaba se ajustando à classe majoritária e isso gera resultados imprecisos, que não refletem a realidade e para contornar isso, é que existem as técnicas de balanceamento de dados.
Com o avanço das tecnologias de sequenciamento de nova geração, o número de dados disponíveis em bancos de dados aumentaram exponencialmente, e as análises de dados estão cada vez mais frequentes, com isso, entender como balancear dados, de longe, já tornou-se importante.

Jean Rodrigues
Um quase biotecnologista que se apaixonou pelo desenvolvimento de softwares, especialmente para bioinformática e um aspirante a cientista de dados. Um observador nato das nuances da vida e amante do canto.
Cite este artigo:
RODRIGUES, J. Dados desbalanceados: Ensinando o seu modelo a maneira certa de aprender. Revista Blog do Profissão Biotec. V. 10, 2023. Disponível em: <https://profissaobiotec.com.br/dados-desbalanceados-ensinando-seu-modelo-maneira-certa-aprender/>. Acesso em: dd/mm/aaaa.
Referências
AZANK, Felipe e GURGEL, Gustavo Korzune. Dados desbalanceados – O que são e como lidar com eles. Turing Talks, set. 2020. Disponível em: https://medium.com/turing-talks/dados-desbalanceados-o-que-s%C3%A3o-e-como-evit%C3%A1-los-43df4f49732b. Acesso em: 10 jan. 2022.
ELHASSAN, A.T.; ALJOURF, M.; AL-MOHANNA, F.; SHOUKRI, M. Classification of Imbalance Data using Tomek Link (T-Link) Combined with Random Under-sampling (RUS) as a Data Reduction Method. Global Journal of Technology and Optimization, v. S1, n. 111, jan. 2016. DOI: 10.4172/2229-8711.S1111. Disponível em: https://www.researchgate.net/publication/326590590_Classification_of_Imbalance_Data_using_Tomek_Link_T-Link_Combined_with_Random_Under-sampling_RUS_as_a_Data_Reduction_Method. Acesso em: 10 jan. 2022.
SUN, Yanmin; WONG, Andrew; KAMEL, Mohamed. Classification of imbalanced data: a review. International Journal of Pattern Recognition and Artificial Intelligence, v. 23, n. 04, p. 687 – 719, jun. 2009. DOI:https://doi.org/10.1142/S0218001409007326. Disponível em: https://www.worldscientific.com/doi/abs/10.1142/S0218001409007326. Acesso em: 10 jan. 2022.
Fonte da imagem destacada: Vecteezy.


Lindo