")
")
É errando que se aprende
Quando iniciamos o nosso desenvolvimento, logo após o nascimento, somos instigados a investigar o mundo e tentar entendê-lo. Isso a todo momento, desde aprender a falar até ao nosso andar.
Pensemos no momento que estamos aprendendo a andar… como funciona?
Uma vez que é possível firmar o pé e ficar em pé no chão, o bebê irá procurar o seu alvo, a mamãe (ou o papai). Mas, para chegar até o alvo, ele precisará desviar de alguns obstáculos como o sofá… o cachorro…o armário…opaa caí… de certa forma até que ele possa acertar o caminho corretamente, para quando chegar até o destino e enfim receber aquele carinho e a mamadeira como recompensa.
Pronto!! Podemos definir esse ciclo como de tentativa e erro, já que desde os primórdios conseguimos definir um caminho para chegar ao objetivo. Acredite ou não, o Aprendizado por reforço também se dá por tentativa e erro, bem semelhante a nós, contando também com o esquema de recompensas.

#ParaTodosVerem: Imagem de conteúdo com animação, na qual se encontra o personagem da animação Futurama, o bebê robô Bender Bending, brincando com cubos com as faces de preenchidas por “0” e “1” em cada face, ele está empilhando os cubos.
Aprendizado por Reforço
Sendo assim, quando vamos para os bits a fim de replicar esse comportamento de tomada de decisão, é necessário se utilizar de certos conceitos e algoritmos. Dessa forma, o aprendizado por reforço é uma técnica de Machine Learning que consiste em programar um agente que irá aprender sozinho a desempenhar uma tarefa com base na sua experiência gerada pela tentativa e erro, sendo o seu feedback suas ações.
A inteligência artificial (IA) irá enfrentar situações em um determinado ambiente, utilizando assim a tomada de decisão para encontrar a solução para o problema. Desse modo, a IA receberá recompensas ou penalidades pelas suas decisões executadas, até que ela consiga atingir o seu objetivo.
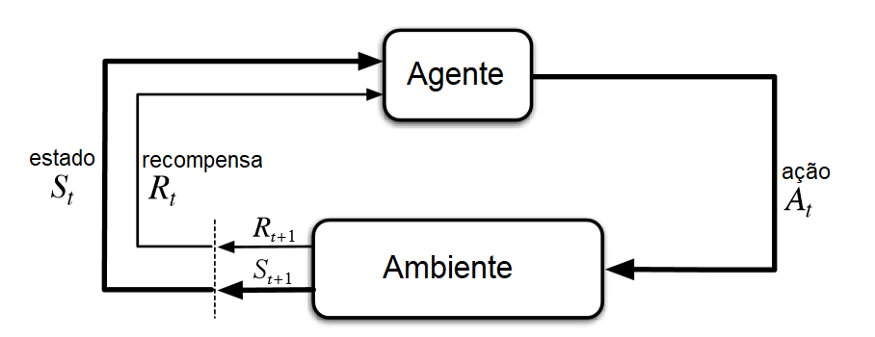
As duas variáveis mais envolvidas no processo de aprendizado por reforço são o agente e o ambiente, quando pensamos em como funcionaria a forma de tomada de decisão temos um algoritmo para nos auxiliar denominado: Processo de Decisão Markov (MDP)
Envolvidos no MDP
Então vamos falar mais sobre alguns conceitos desse processo todo da tomada de decisão. O MDP é uma abordagem matemática que mapeia soluções de reinforcement learning (RL, aprendizado de reforço, em tradução livre). O MDP providencia um framework de RL, também conhecido como máquina de estados, que pode resultar em uma sequência de estados randômicos ou parcialmente controlados. Os parâmetros abaixo compõem todo esse framework:
> Agente: é a entidade que realizará a tomada de decisão podendo ser um software ou hardware. Ele interagirá com o ambiente executando as ações a fim de receber recompensas ou punições. Ele efetivamente aprenderá por Aprendizado de reforço.
>Ambiente: Onde o agente realizará suas ações, essa simulação pode ser real (aplicações robóticas) ou virtual (softwares).
>Estado (s): A alteração de estados do sistema, sempre que o agente executa uma determinada ação no ambiente o seu estado é alterado.
>Política (π): A estratégia seguida pelo agente ao tomar uma decisão.
>Recompensa (r): O resultado das ações executadas pelo agente, a partir de determinado estado desejado , pode ser uma recompensa positiva, ou negativa.
Essa transição de estados ocasionado pelo agente em uma ambiente pode ser representada pela seguinte expressão matemática (Equação 1):
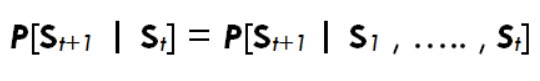
Vamos ilustrar esse fluxo com um exemplo do cotidiano:
Pense no cotidiano de um aluno de pós-graduação (Mestrado/Doutorado…), que transita entre 3 estados: dormir, escrever e comer doce (haha combustível). Caso ele esteja escrevendo muito, haverá 30% de probabilidade de continuar e 10% de parar para comer um brigadeiro, e 60% de ir dormir. Sendo assim, para cada estado que esse estudante escolher haverá uma probabilidade que poderá variar com a sua própria escolha.
Dessa forma a transição de estado pode ser definida mais uma vez pela recompensa através da tomada de determinada ação.
Nesse contexto a função política (π), mapeia as probabilidades de determinado estado ser selecionado mediante a ação. Essa política será atualizada até atingir a configuração ótima (quando o agente executa sua função corretamente).
Portanto, no exemplo acima, a política ótima para um estudante de alta produtividade no mundo ideal (hehehe) seria que ele gastasse 60% de sua energia escrevendo, 10% para uma pausa (com um café e um bolinho) e 30% para o descanso.
E ao final, o diagrama que mais representaria o Aprendizado por Reforço seria como o ilustrado abaixo:
Aplicações em Biotec
Mas como será que podemos aplicar todas essas programações na biotecnologia?
Pois bem, atualmente nós temos um forte incentivo para o fim da utilização de combustíveis fósseis a fim de preservar o meio ambiente… ou o que resta dele…
Sendo assim, os carros elétricos começaram a se tornar uma realidade cotidiana, além é claro de se ter todo o desenvolvimento de uma nova tecnologia mecânica, o ML e a utilização de aprendizado de reforço são de extrema importância para treinar o piloto automático a desviar dos obstáculos e garantir assim uma viagem mais segura. Thanks, Elon Musk!

#ParaTodosVerem: Imagem de conteúdo com animação do filme “I, robot”, na qual se encontram duas pessoas dentro de um carro, e a mulher (surpresa) pergunta se o homem irá dirigir utilizando as mãos, uma vez que o carro está no piloto automático.
Na bioinformática também temos um grande Boom! de algoritmos que podem auxiliar a montagem de DNA, caracterização do movimento celular, migração celular coletiva. Nesse último caso, podendo ser de grande ajuda no desenvolvimento de novos fármacos ou criação de modelos a fim de predizer efeito colateral de medicações ou doenças. Nesse contexto, podemos criar um modelo para realizar a montagem de fragmentos de DNA.
Sendo essa, uma técnica que visa reconstruir uma sequência original a partir de um grande número de fragmentos, determinando assim a ordem em que os fragmentos devem ser montados de volta na sequência do DNA origina, com a utilização da aprendizagem por reforço podendo até ser combinada com outras abordagens disponibilizadas pelo machine learning. As possibilidades são infinitas, precisamos apenas continuar nos perguntando para criar.
Continue seguindo essa série para mais informações sobre as diversas áreas da inteligência artificial e machine learning!

Samilla B.
Biografia:
Doutoranda em Biotecnologia pela (UCDB), estudando biofísica computacional com enfoque em estrutura de proteínas. Fascinada pelas possibilidades que a bioinformática pode promover.
Cite este artigo:
SAMILLA B. O reforço de cada dia, recompensas e punições no cotidiano computacional. Revista Blog do Profissão Biotec. V. 10, 2023. Disponível em: <https://profissaobiotec.com.br/reforco-de-cada-dia-recompensas-punicoes-no-cotidiano-computacional/>. Acesso em: dd/mm/aaaa.
Referências:
Deep Learning Book – Capítulo 62 – O Que é Aprendizagem Por Reforço? Disponível em: https://www.deeplearningbook.com.br/o-que-e-aprendizagem-por-reforco/. Acesso em 14/09/2021.
JÚNIOR, Eugênio Pacelli Ferreira Dias; RODRIGUES, Paulo Gallotti; ENDLER, Markus. PUC. Disponível em: https://www.maxwell.vrac.puc-rio.br/19637/19637_4.PDF. Acesso em 14/09/2021.
GeeksforGeeks – Reinforcement learning. Disponível em: https://www.geeksforgeeks.org/what-is-reinforcement-learning/.Acesso em 14/09/2021.
https://medium.com/turing-talks/aprendizado-por-refor%C3%A7o-1-introdu%C3%A7%C3%A3o-7382ebb641ab.
Bernardo Coutinho – Aprendizado por Reforço: Introdução. Disponível em: https://medium.com/@bernardo.rcoutinho/aprendizagem-por-refor%C3%A7o-introdu%C3%A7%C3%A3o-ff159c2ec9b. Acesso em 14/09/2021.
Fonte da imagem destacada: Unsplash.


")
