")

Este é o #7 texto da Série Especial sobre Engenharia Metabólica.
Com o advento das novas tecnologias de sequenciamento (NGS), uma elevada quantidade de informações biológicas são produzidas diariamente. A maior disponibilidade de genomas de microrganismos sequenciados possibilita que bioinformatas utilizem algoritmos para tentar explorar e entender melhor a informação codificada dentro do DNA dos organismos.
A análise in silico de microrganismos é uma área da ciência que está em amplo crescimento nos últimos anos, com destaque ao enfoque na utilização de ferramentas computacionais para predição de rotas metabólicas. O intuito de tais abordagens é a busca pela integração de conhecimentos multidisciplinares a respeito da biologia molecular, fisiologia e bioquímica do organismo, criando modelos computacionais que imitam o funcionamento do organismo in vivo.
Esses modelos podem auxiliar os cientistas a descobrir vias metabólicas ainda não descritas e interações ainda não avaliadas, assim sendo uma valiosa abordagem para fins de engenharia metabólica. Caso não tenha muita familiaridade sobre engenharia metabólica e queira ficar um pouco mais por dentro do tópico, sugiro a leitura do texto: O que é engenharia metabólica, que está aqui no blog.
Mas você deve estar se perguntando, como isso é possível certo? Bom, para isso devemos iniciar nossa conversa explicando alguns conceitos básicos…
Caso não tenha muita familiaridade sobre engenharia metabólica e queira ficar um pouco mais por dentro do tópico, sugiro a leitura do texto: O que é engenharia metabólica, que está aqui no blog.
O que é bioinformática?
A bioinformática é um ramo da biologia computacional, que estuda informação de sistemas biológicos, em particular, informações moleculares dos blocos de construção das células (os metabólitos, as proteínas e os Ácidos Nucleicos – RNA e DNA), empregando conceitos de informática, como a utilização de computadores e desenvolvimento de algoritmos, com finalidade de estudar e compreender os organismos através de modelos. Assim, busca entender quais são as substâncias que compõem um organismo vivo e como elas interagem entre si. Além da parte computacional, a biologia desempenha um papel fundamental nessa ciência, pois são com os conhecimentos biológicos que conseguimos validar e verificar se os algoritmos e modelos estão produzindo resultados biologicamente relevantes.
Uma definição um pouco mais formal seria: A aplicação de ferramentas computacionais para organizar, analisar, entender, visualizar e guardar informações associadas às moléculas biológicas.
O que são rotas metabólicas?
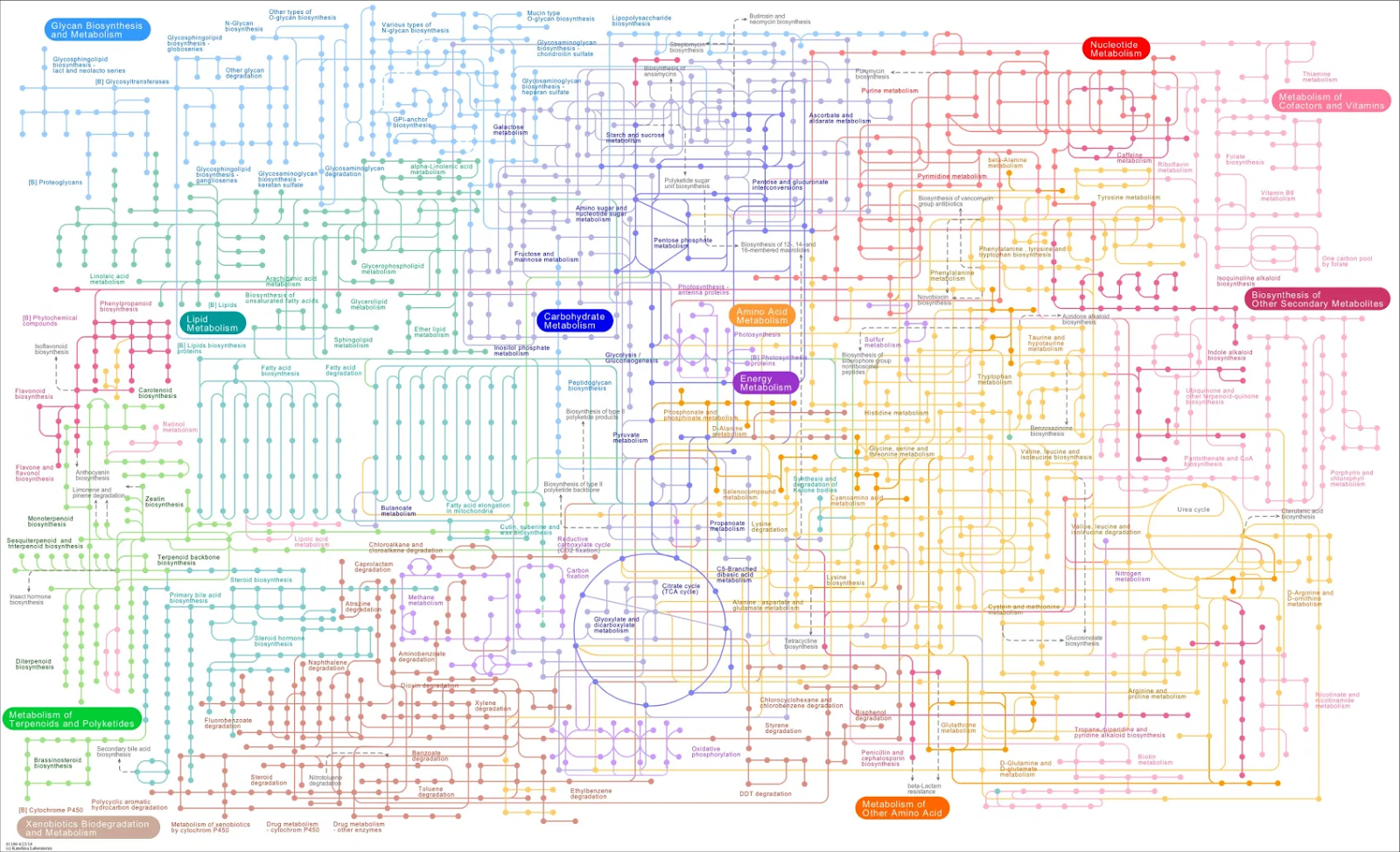
Rotas ou Vias Metabólicas são sequências de reações químicas entrelaçadas pela relação substrato-enzima-produto. Existe uma lógica de dependência entre reações dentro do organismo: um substrato (composto inicial a ser usado como matéria prima) é utilizado por uma enzima (molécula biológica com estrutura ordenada, capaz de realizar reações químicas, ou seja, modificar moléculas), que gera um produto que por sua vez é o substrato de outra enzima, assim ocorrendo uma nova reação. Esse ciclo se perpetua até que um determinado equilíbrio ou demanda seja atingido, sendo controlados pelo organismo, que é capaz de detectar mudanças no ambiente e regular o metabolismo.
Um exemplo clássico é a via da glicólise (quebra da glicose).

As relações entre entre substrato e produto são aceleradas pela presença das enzimas, mas não só por elas, os cofatores ( pequenas moléculas que atuam diretamente sobre a atividade enzimática, sendo fundamentais para seu funcionamento) também desempenham um papel importante na atividade enzimática.
De maneira geral, as vias metabólicas possuem elevada complexidade, comportando-se como uma rede de conexões (rede metabólica). Essa rede de conexões é fundamental para que o organismo consiga sobreviver, pois permitem que aminoácidos essenciais, o ATP e diversas outras substâncias importantes para a sobrevivência sejam produzidas. Devido a essa característica, as vias podem ter diversos comportamentos desde vias metabólicas cíclicas, onde o produto final da via é o substrato inicial para seu funcionamento, ou vias lineares, onde necessitam de um substrato de outra via ou do ambiente para produzir um produto que vai ser usado em outras vias ou liberado no ambiente.

Bancos de dados sobre vias e sua composição
Bom, já deu para notar que o estudo de vias metabólicas envolve uma série de conceitos complexos, desde enzimas que catalisam as reações, metabólitos (moléculas produzidas em uma reação) e toda a conexão entre diversos componentes dentro do organismo. Para podermos estudar de maneira lógica, essas informações precisam ser guardadas de maneira adequada. Para isso existem os bancos de dados de vias metabólicas. É importante entender, que estes bancos são o resultado conjunto do conhecimento adquirido com a caracterização detalhada de genes, enzimas e metabólitos. Portanto, como veremos na sequência, os catálogos de mapas metabólicos de organismos vivos representam a informação para construção e regulação do metabolismo, codificadas nos genes, e o potencial metabólico mapeado nas enzimas e metabólitos. Por isso, conhecer o ecossistema original do organismo, e sua história evolutiva, é essencial para entender como o genoma evoluiu, e consequentemente, como o metabolismo é regulado.
KEGG
O KEGG é um dos bancos de dados mais utilizados pelos pesquisadores, em diversas áreas da biologia, para o estudo do metabolismo. Seu acervo conta com uma série de informações curadas (verificadas por especialistas) associadas a Biologia de Sistemas (área da biologia que usa a bioinformática para estudar as vias metabólicas), desde dados sobre a composição celular, local de ocorrência natural do organismo, enzimas e reações químicas.
ModelSEED
O ModelSEED é uma ferramenta e banco de dados que cria, avalia e analisa modelos de vias metabólicas. Em relação ao banco de dados, ele contém informações acerca da bioquímica de diversos organismos, desde reações, enzimas, produtos produzidos e meios de cultura utilizados pelos organismos. Além disso, conta com alguns modelos computacionais de vias metabólicas. Esse banco de dados possui alguns diferenciais em relação aos competidores, como a compartimentalização de reações químicas, inclusão de reações de transporte e equações químicas balanceadas.
MetaCyc
O MetaCyc é outro banco de dados muito utilizado na área de biologia de sistemas. O banco contém informações sobre diversas vias metabólicas e enzimas de diversos organismos. A grande maioria dos dados encontrados são curados através de experimentos laboratoriais, o que fornece grande segurança na utilização da informação para construção de novos modelos. A ferramenta se destaca pela vasta informação acerca das especificidades das enzimas, descrevendo estruturas, cofatores envolvidos, fatores de ativação e inativação, substratos necessários para atividade e constantes cinéticas.
Outros …
Muitos outros bancos de dados existem, como por exemplo o BIGG que contém modelos computacionais curados para uma série de organismos, além de informações curadas acerca de diversas vias metabólicas e seus integrantes. BRENDA é outro repositório muito utilizado, sendo seu maior foco a detecção de enzimas e suas funcionalidades.
A problemática dos bioinformatas
Apesar da grande quantidade de informações disponíveis para estudo, a integração de todo esse material em um único repositório é muito difícil, pois cada banco de dados possui nomenclaturas diferentes para a identificação das reações e metabólitos. Assim, a junção da informação se torna complexa, demandando a utilização de algoritmos especializados para compilação, comparação e integração de diferentes fontes de informação. Este processo geralmente requer a intervenção de um grupo multidisciplinar com biólogos, bioquímicos, químicos e cientistas da computação, para inspeção e validação da informação integrada.
Bom, agora que já sabemos um pouco mais sobre os pilares da bioinformática e da biologia de sistemas, podemos falar sobre como criamos esses modelos!
Criando modelos de vias metabólicas
A seguir explicaremos para vocês de maneira simplificada o passo a passo de como criar um modelo metabólico de um microrganismo utilizando uma das principais abordagens aplicadas, o FBA ou Análise de Balanço de Fluxo.
FBA
Na Análise de Balanço de Fluxo (do inglês Flux Balance Analysis – FBA), a Via Metabólica do organismo em questão é representada por um conjunto de equações matemáticas as quais equivalem às reações bioquímicas que ocorrem dentro do organismo. Nesta abordagem são definidas funções objetivas que podem ser, por exemplo, o crescimento do microrganismo ou a produção de um determinado composto. A meta do modelo é encontrar o valor máximo possível para a função objetivo.
Uma das principais vantagens da utilização do FBA é a possibilidade de alimentar o modelo com informações avaliadas e curadas, auxiliando o modelo a se tornar ainda mais robusto, resultando na produção de predições mais precisas. Além disso, é um tanto (relativamente) simples utilizar essa abordagem para avaliar o possível efeito de knockout gênico (remoção ou “deleção” de um gene): basta alterarmos o valor da cinética enzimática (a velocidade das reações enzimáticas é representada por constantes para cada enzima, ou seja, pela sua cinética enzimática) da enzima associada ao gene em questão, assim todos os produtos que dependem dela para sua produção serão removidos da reconstrução, alterando o fluxo da função objetivo. Desta forma, temos um método para avaliar se uma modificação no genoma de uma célula produtora irá resultar no aumento da nossa meta, definida por nossa “função objetivo”.
Passo a passo
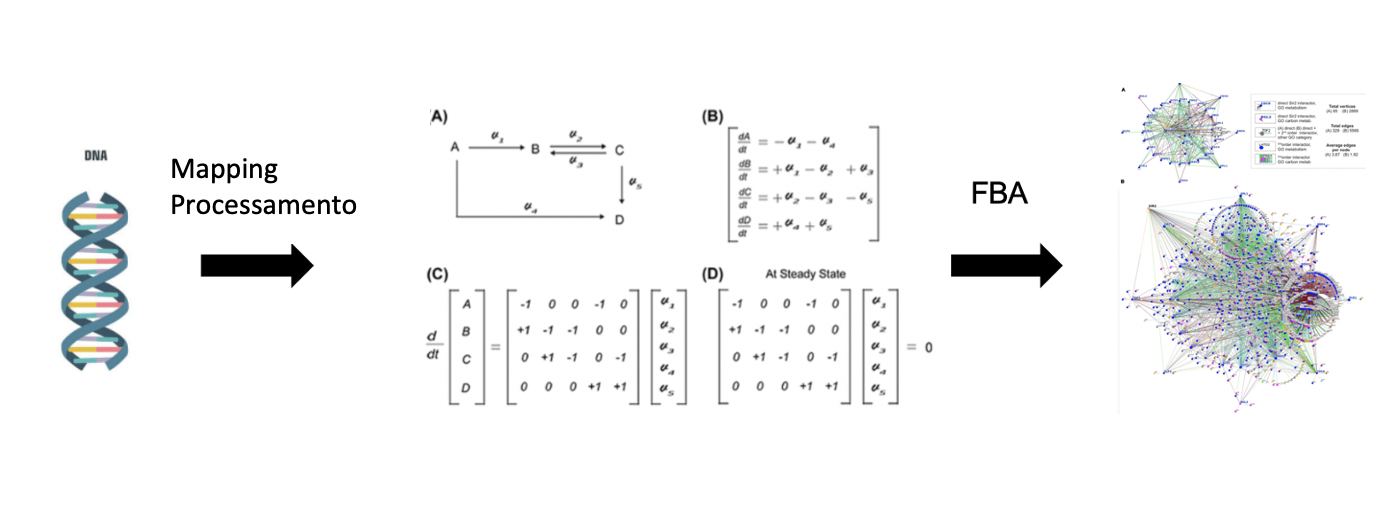
Primeiramente, precisamos definir qual organismo iremos estudar, em seguida precisamos extrair seu DNA e sequenciá-lo. Caso o genoma do organismo esteja disponível, basta coletarmos as informações do genoma de algum banco de dados, como NCBI (National Center for Biotechnology Information), por exemplo.
Em seguida, precisamos identificar quais são as funções dos genes no genoma, processo conhecido como mapeamento genético (mapping). Durante o mapeamento, as regiões codantes (codificadoras, quegeram proteínas) são identificadas e com isso podemos ir em busca dos números EC(EC-numbers), que são classificadores das proteínas e indicam em quais reações elas se envolvem na via metabólica. Para isso, utilizamos as informações sobre enzimas contidas nos bancos de dados….
Através de um árduo processo podemos finalmente identificar a relação entre Genes (DNA) -Enzimas (Proteínas) – Reações, etapa fundamental na modelagem. Em seguida, precisamos transformar essas informações bioquímicas em modelos matemáticos, para assim utilizarmos o FBA.
A transformação da bioquímica em equações lineares de um modelo matemático gera o que os pesquisadores chamam de S matrix, ou Matriz estequiométrica. Essa matriz é utilizada como base para que os bioinformatas utilizem algoritmos para identificar qual o fluxo (quão ativa as reações são) e assim otimizar a produção da função objetivo que, como mencionado anteriormente, pode ser o crescimento de microorganismos.
Parece complexo, né? Realmente é! Se você ficou interessado sugerimos a leitura do artigo: A protocol for generating a high-quality genome-scale metabolic reconstruction, que explica detalhadamente cada uma das etapas. Boa leitura!
Mas afinal, quais as vantagens de se modelar as vias metabólicas?
- Identificar as principais reações metabólicas;
- Entender o que acontece se um gene for deletado;
- Identificar rotas metabólicas que possam estar “competindo” e “roubando” carbono da via metabólica de interesse;
- Manipular com auxílio da Biologia Sintética determinados componentes da rota, otimizando a produção de compostos de interesse;
- Recentes descobertas disruptivas, como a melhoria na predição da estrutura de proteínas, permitem vislumbrar avanços até pouco tempo tidos como impossíveis, como a assimilação de CO2 por bactérias para produção de alimentos, combustíveis ou precursores sintéticos.
- E milhares de outras possibilidades, o limite é a imaginação !
Ao longo do texto, vimos como a bioinformática pode ser usada para a predição de rotas metabólicas, como são os bancos de dados dessas vias metabólicas e como elas podem ser criadas. Esse universo está apenas se iniciando, as possibilidades de criação são infinitas, e nos próximos anos veremos todos os benefícios que essa tecnologia irá gerar para nossa sociedade, melhorando nosso sistema produtivo e reduzindo impactos no meio ambiente.

Cite este artigo:
TAMASCO, G. Análises in silico: a bioinformática para predição de rotas metabólicas. Blof do Profissão Biotec. V. 7, março 2021. Disponível em: <www.profissaobiotec.com.br/analise-in-silico-bioinformatica-predicao-de-rotas-metabolicas>



